SemanticPOSS: A Point Cloud Dataset with Large Quantity of Dynamic Instances
Overview
-
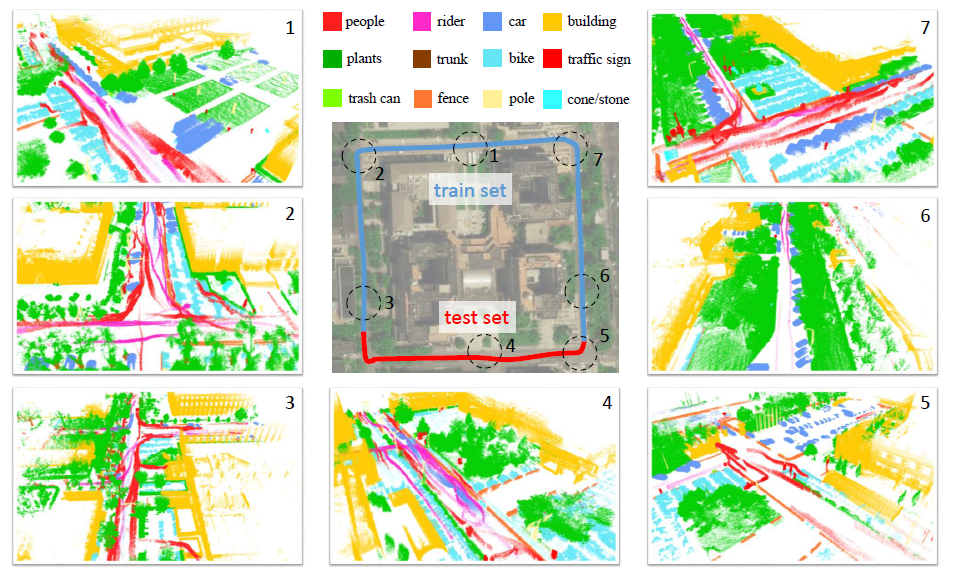
We present the SemanticPOSS dataset, which contains 2988 various and complicated LiDAR scans with large quantity of dynamic instances.
The data is collected in Peking University and use the same data format as SemanticKITTI .
The dataset is used for semantic segmentation task. And for convenience, the provided dataset uses the same data format and interface as SemanticKITTI.
Classes and data format
-
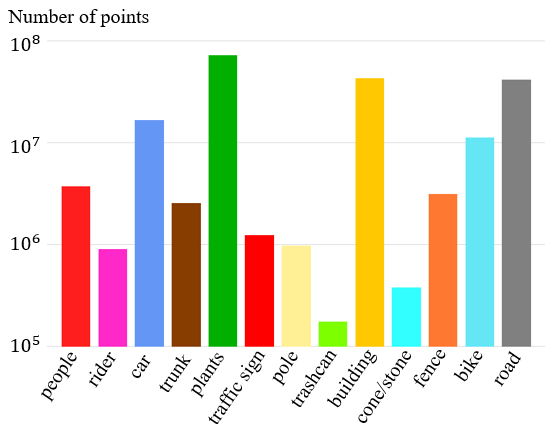
The dataset contains 14 classes: unlabeled(0), people(4,5), rider(6), car(7), trunk(8), plants(9), traffic sign(10,11,12), pole(13), trashcan(14), building(15), cone/stone(16), fence(17), bike(21), ground(22).
The folder structure and data format are same as the SemanticKITTI dataset. File XXXXXX.bin in velodyne folder is the point cloud data. File XXXXXX.label in the labels folder contains a label in binary format for each point. The label is a 32-bit unsigned integer for each point, where the lower 16 bits correspond to the label. The upper 16 bits encode the instance id, which is temporally consistent over the whole sequence. File XXXXXX.tag in the tag folder is used for generating range image, which records the position of each point in range image.
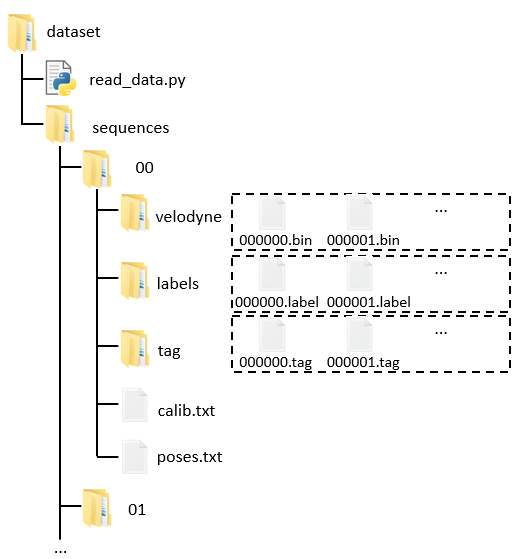
In addition, we provide some simple functions for reading data and labels in read_data.py file. The file is in the dataset folder.
Download
Cite
- @misc{pan2020semanticposs,
title={SemanticPOSS: A Point Cloud Dataset with Large Quantity of Dynamic Instances},
author={Yancheng Pan and Biao Gao and Jilin Mei and Sibo Geng and Chengkun Li and Huijing Zhao},
year={2020},
eprint={2002.09147},
archivePrefix={arXiv},
primaryClass={cs.RO}
}
License
- This dataset follow Creative Commons Attribution-NonCommercial-ShareAlike 3.0 License.